
1. 인공지능
→ 인간의 지능적 능력을 인공적으로 구현하려는 컴퓨터 과학의 세부 분야
→ 컴퓨터 역사와 같음
1940~1960 : cybernetics (인공두뇌학)
- Electronic Brain : 튜닝머신 - 판단관이 사람인지 시스템인지 판단 → 판단관을 속이면 인공지능
이후 인공지능의 판단 기준을 만들고 인간처럼 기계도 학습시키기 위해 사람의 뇌를 모방하기 시작하며 인공두뇌학을 개척
- Perceptron : 뇌의 뉴런을 모방(단일 세포)—> 그러나 인간의 뇌는 단일구조가 아님
- → ADALINE으로 발전
- XOR Problem : 퍼셉트론은 공간의 이분화가 가능한 OR문제는 해결이 가능하지만 XOR 문제는 해결 못 함
1980~1990 : connectionism
- Multi-layered Perceptron : 뉴런이 서로 연결되어 전기적 신호를 주고 받는 것을 모방하여 만들어짐 → 두 개의 perceptron을 서로 연결시켜 확장함
- SVM
→ 그러나 이 또한 뉴런이 복잡하게 연결되어있는 인간의 뇌를 모방하긴 어려워서 발전이 더뎌짐
2006~현재 : deep learning
- Deep Neural Network (Pretraining) : 심층학습이 발달 (과거 인공지능 개념들이 인간의 뇌와 흡사하게 대확장됨)
인공지능 범주와 범주에 따른 주요 요소 세분화
- AI : 인간의 지능을 모방하려는 모든 기술을 인공지능이라 함
- Machine learning : 기계학습 (사람의 학습(지능)을 모방)
- Representation learning : 표현학습
- Deep learning : 심층학습
인공지능과 컴퓨터과학은 다음과 같은 순으로 발달되어옴
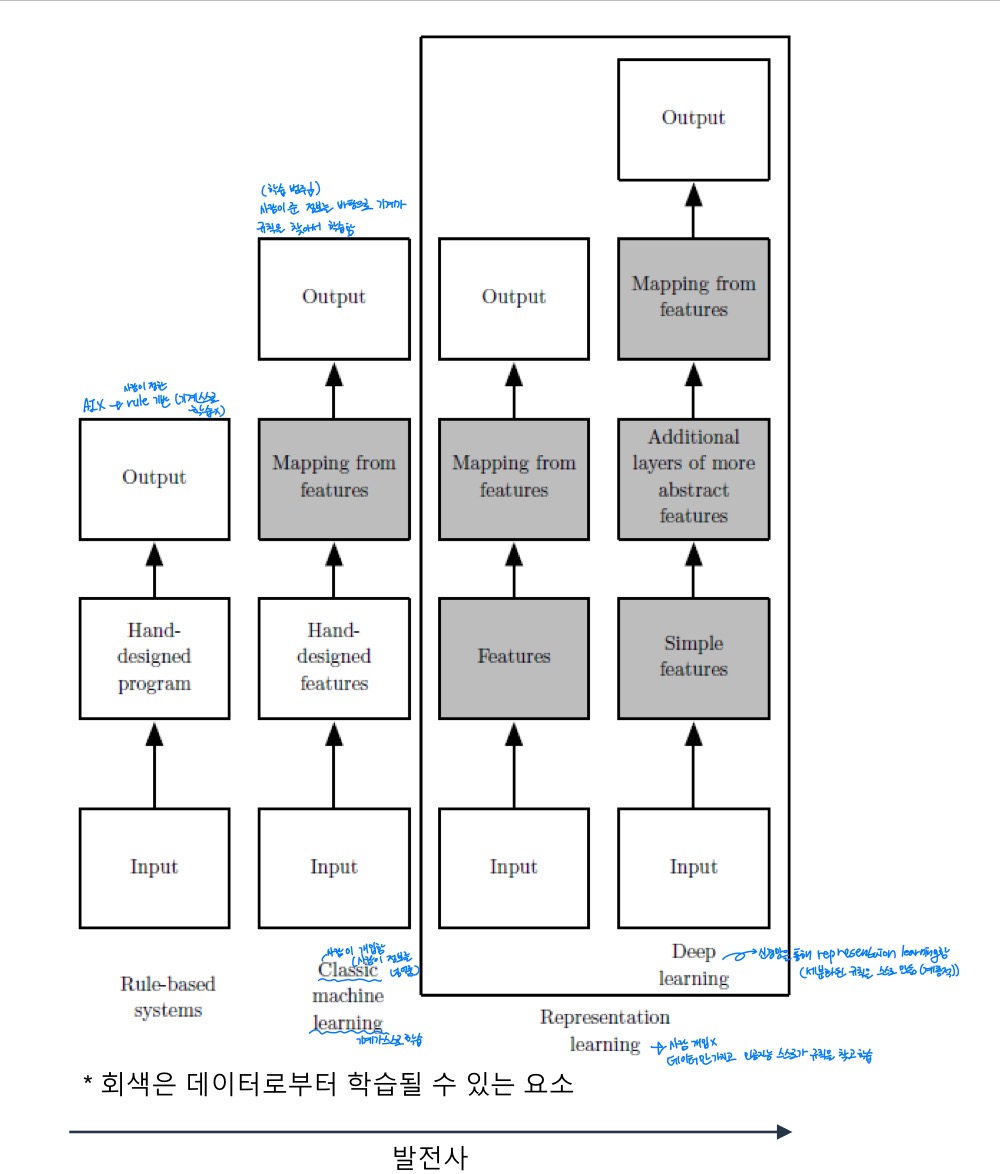
- Rule-based Systems : Input → Hand-designed program → Output
- → AI는 아님, 사람이 정한 rule에 기반하여 output을 만들어 냄 (기계 스스로 학습하지 않음)
- Classic machine learning : Input → Hand-designed features → Mapping from features → Output→ 그러나 사람이 준 정보를 바탕으로 기계가 규칙을 찾아서 학습함 (학습의 범주가 얕음)
- → Mapping from features는 기계가 스스로 학습한 요소
- Representation learning → 사람 개입x / 데이터만 가지고 인공지능 스스로가 규칙을 찾고 학습
- Input → Features → Mapping from features → Output
- Deep learning : Input → Simple features → Additional layers of more abstract features → Mapping from features → Output→ 세분화된 규칙을 스스로 계층적이게 만듦
- → 신경망을 통해 representation learning함
2. 기계학습
학습 : 경험의 결과로 나타나는 지속적인 행동의 변화나 잠재력의 변화 혹은 지식을 습득하는 과정
기계학습
→ 경험을 통해 점진적으로 원하는 성능에 도달할 수 있는 기계
- PTE 논리 : 어떤 컴퓨터 프로그램이 T라는 주어진 작업을 수행하고 성능을 P라는 척도로 평가할 때, 경험 E를 통해 성능이 개선 된다면 해당 프로그램은 학습을 한다 라는 논리
즉, E * T = P : E를 통해 T를 수행하는 기계의 P가 점진적으로 개선된다면 기계학습이라는 것
→ 반드시 전보다 성능이 개선되어야 한다. 안 되면 기계학습 x
→ 목표는 최적의 프로그램(알고리즘)을 찾는 것
전통적인 프로그래밍과 기계학습의 차이
기계학습의 유형
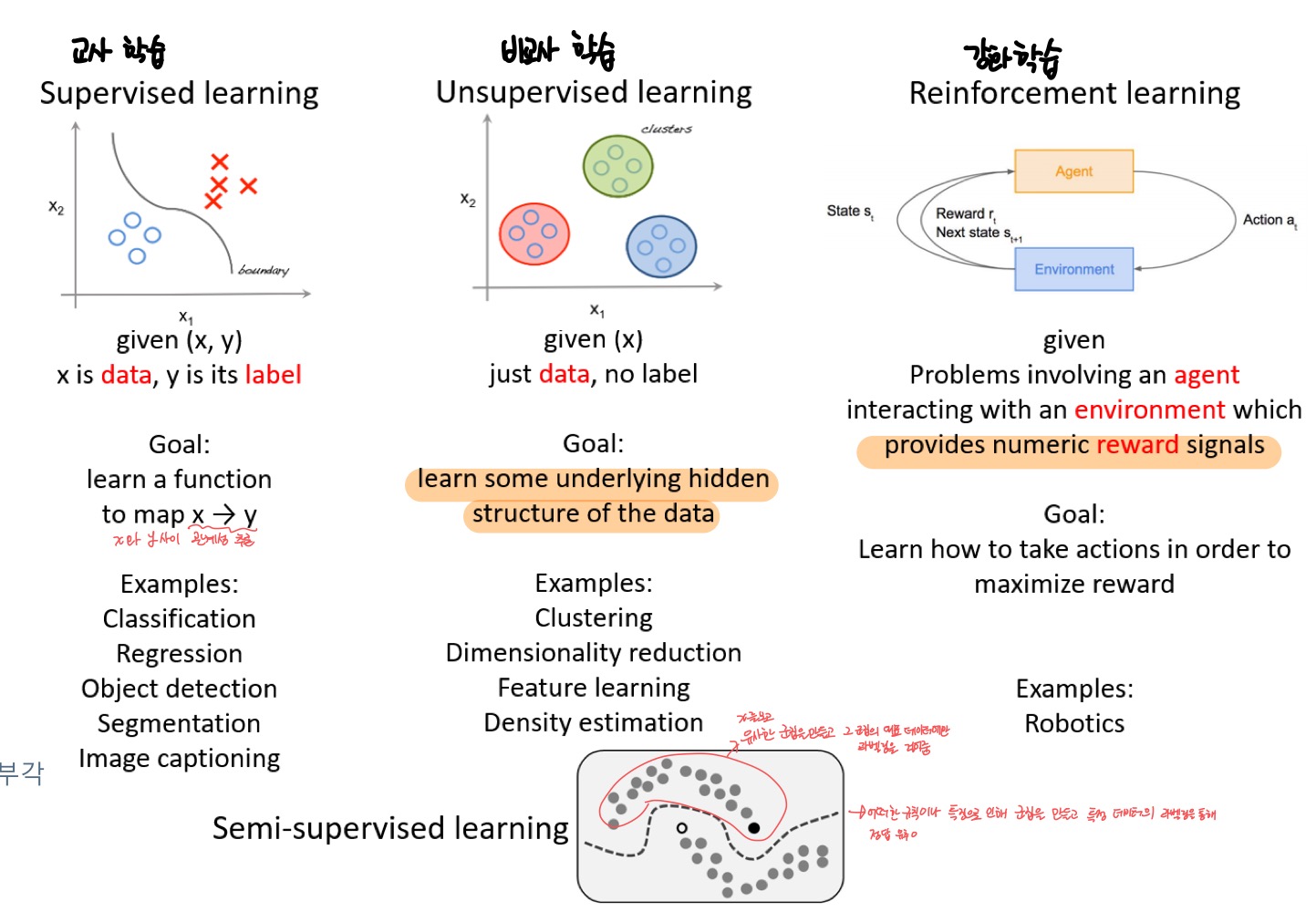
교사학습 supervised learning
- 특정 벡터X(data)와 목표치Y(result)가 모두 주어진 상황
- 회귀와 분류 예측 과업으로 구분 : 회귀와 분류는 예측을 위한 task (회귀/분류로 구분될 뿐)
- 회귀 regression
- 분류 classification : x와 y를 같이 알려주어 y에 대한 x값들의 특징을 쉽게 찾을 수 있도록 해줌
비교사학습 unsupervised learning
- 특정 X는 주어지나 Y는 안 주어짐
- data가 갖고 있는 군집(특징)을 찾고 분류함
- 군집화 clustering
- 밀도 추정 density estimation, 특징 공간 변환 과업 (3에서 더 자세히)
강화학습 reinforcement learning
- 상대적 Y가 주어지나 지도 학습과는 다른 형태 (result 보다는 reward) (교사학습과 비슷)
- → 즉, output이 상대적이라는 말 → reward를 최고 수준으로 만드는 최적의 결과값을 찾아야 함
ex) 바둑처럼 판세를 읽고 기계가 어디에 돌을 놔야하는지에 대해 기계 자신 스스로의 행동을 학습하는 것임
준교사 학습 semi-supervised learning
- 일부는 X와 Y 모두 가지지만, 나머지는 X만 주어짐
- → X만 보고 비교사학습처럼 유사한 군집을 만들고, 그 군집의 대표 x에만 x에 대한 y를 줌
- 즉, 어떠한 규칙이나 특징으로 인해 군집을 만들고 특정 데이터의 라벨링을 통해 정답을 유추하는 것
- X수집은 쉽지만 Y는 사람이 직접 데이터 라벨링 작업을 해줘야하기 때문에 중요성 부각 됨
기계학습 모델의 유형
online ↔ offline
- online model : 실시간으로 발생하는 데이터를 즉각적으로 수집하여 점진적으로 학습하는 모델
- → P를 점진적으로 강화
- offline model : 데이터집합을 모아서 학습하는 일반적인 모델 (데이터 수집 후 학습)
deterministic ↔ stochastic
- 결정론적 deterministic model : 데이터집합을 가지고 학습하면 늘 동일한 결과를 만드는 모델
- → 변동성 x - 어떠한 x에 대한 y값이 늘 같은 것
- 확률론적 stochastic model : 학습 과정에서 확률적 분포 요소를 추가하여 동일한 데이터 집합이라도 수행할 때마다 다른 결과를 만들 수 있는 모델
- → 변동성 o - 현실에서는 불확실성과 변동성이 존재하여 의도적으로 모델에 확률적 분포를 추가
discriminative & generative
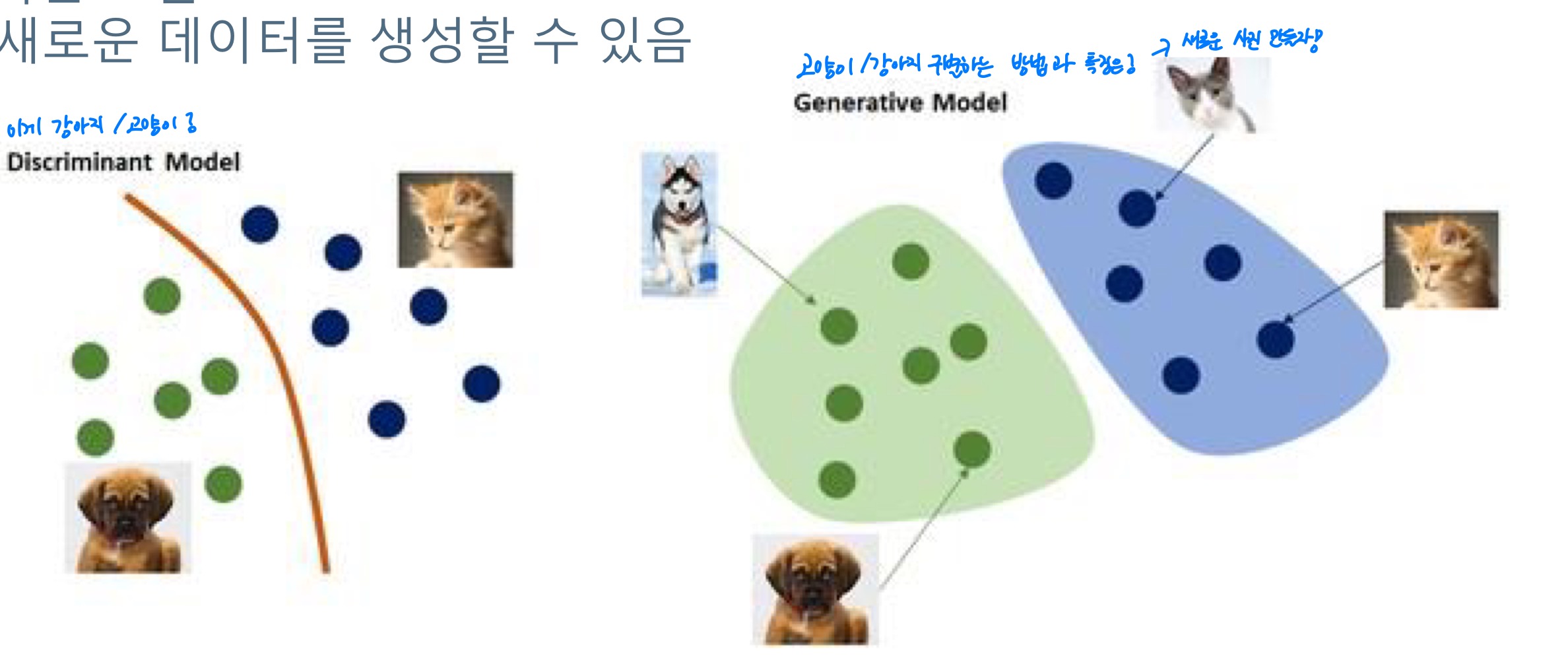
- 분별 discriminative model : 데이터와 정답 간의 관계(P(y|x)) 추정이 목적인 모델→ x→y 를 만들어내는 과정 추정이 목적
- 생성 generative model : 데이터 생성 P(x) 추정이 목적인 모델→ 새로운 데이터를 생성할 수 있음
- → 데이터가 가지고 있는 분포의 특징을 추정하는 것이 목표(새데이터가 어떻게 만들어지는가)
학습 과업 task
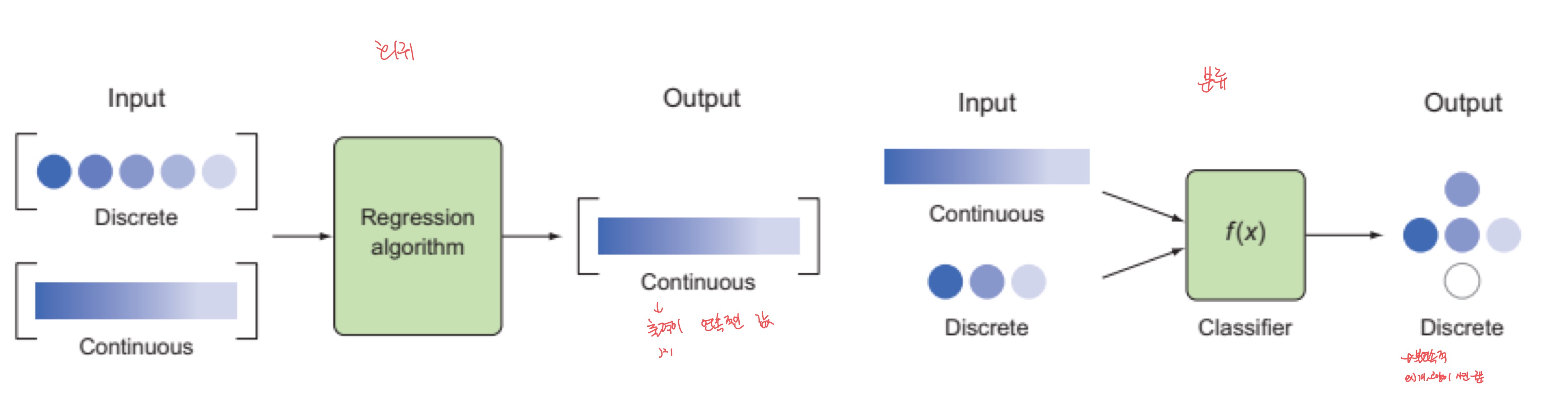
- 분류 classification : 출력이 불연속적인 값
- 회귀 regression : 출력이 연속적인 값
- 이상탐지 anomaly detection : 튀는 데이터를 찾는 과업 / ex) 자이롭센서(애플워치 낙상 방지)
- 밀도 추정 density estimation : 데이터 분포 확률 추정 → 관찰 값으로 분포를 얻어내는 행위
기계학습 필요 조건
- data
- pattern
- non closed-from solution : 수학적으로 설명되지 않는 규칙성을 모델이 근사화하도록 만들어 줌
3. 데이터와 특징 공간
데이터의 중요성
- 기계학습은 데이터에 숨은 규칙을 찾아가는 행위 (generative model 찾기)
- P(x)를 모르는 상황에서 관찰된 데이터(실제 고양이 사진같은)만으로 규칙을 근사 추정해야 함.
- → P(x)를 알 수 없는 것은 기계학습이 어려운 이유 중 하나
예를 들어 고양이 사진이 있다. 고양이 사진에는 pixel값이 존재하고, 고양이 사진에 대한 pixel값에는 사람이 모르는 규칙이 있다.(색, 윤곽선 등등) 이 고양이 사진에서 숨은 규칙(특징, 군집)을 찾아내는 것(generative model - 새로운 데이터를 생성할 수도 있다.)과 고양이 사진을 고양이 사진이라고 분류해내는 과정과 관계를 찾아내는 것(discriminative model 분별 모델)이 기계학습의 목표이다.
→ 충분한 양의 데이터를 수집해야 성능 향상을 기대할 수 있다.
데이터와 특징 공간
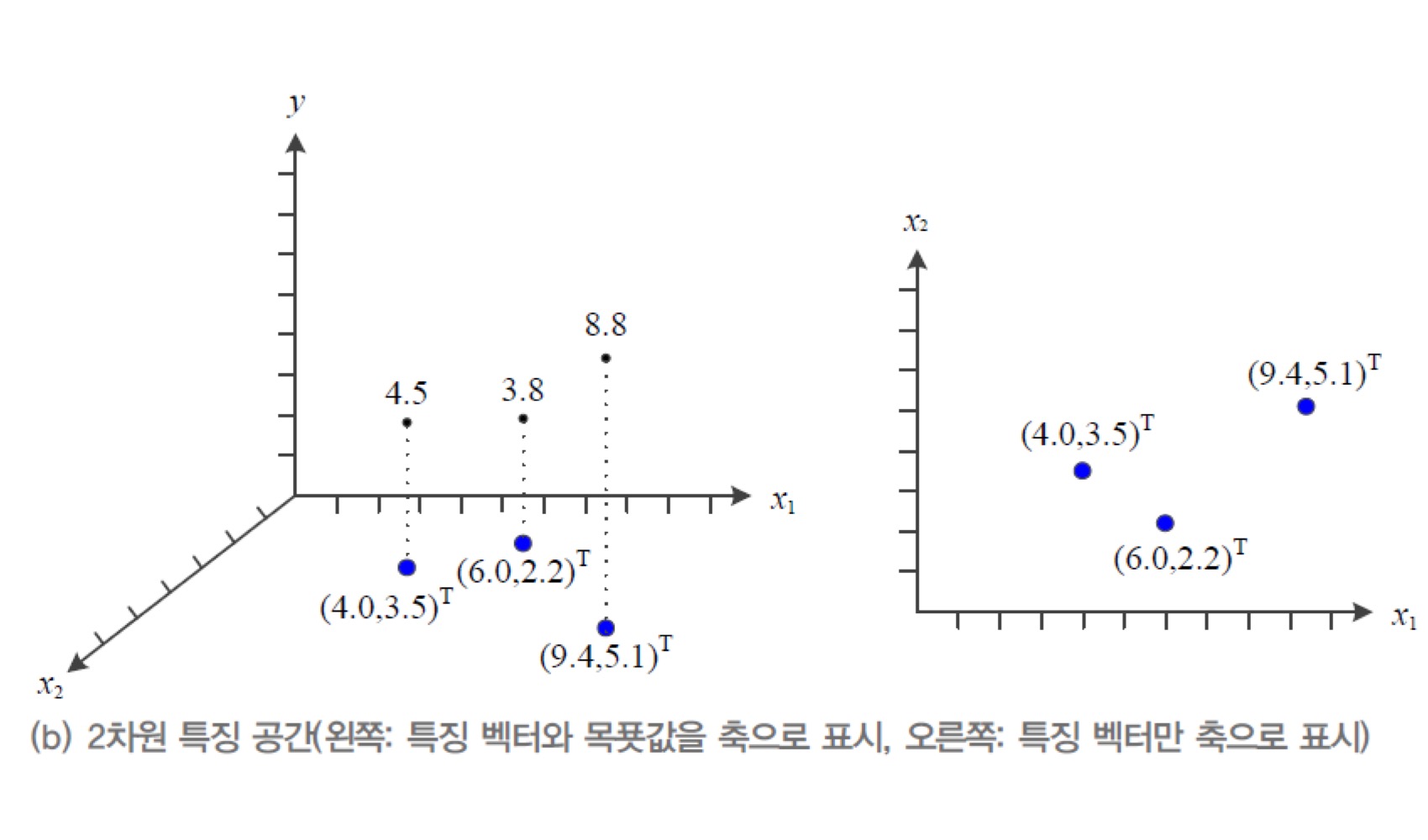
- 모든 관찰 데이터는 정량적으로 표현되며 특징 공간 상에 존재
- 특징 공간 feature space : n차원 공간이라 생각해도 됨
- → n차원 데이터의 특징 벡터를 표기할 땐 $\bold x=(x_1, x_2, ... , x_n)^{T}$ 형식으로 표기
- 두 데이터 $\bold a=(a_1, a_2, ... , a_n)^{T}$ , $\bold b=(b_1, b_2, ... , b_n)^{T}$ 가 있다면 두 데이터 사이의 거리는
- 거리 dist : 벡터에서의 크기 성분 표현 (유클리드 거리)
- 유사도 similarity (내적 inner product) : 내적을 통해 유사도 측정
- 선형 변환 linear transformation (차원 변환)→ 시각화가 가능해짐
- → 선형대수 원리임 - 1xn 행렬과 nxn 대각선 행렬을 곱해서 보이지 않던 특징을 찾아내거나 특정 특징을 부각하거나 할 수 있음
- → 원래 가지고 있던 특징 공간에서의 데이터에서 보이지 않던 특징 추출을 위한 가공
차원의 저주 curse of dimensionality
- 데이터의 차원이 증가할수록 특징 공간의 크기(부피)가 기하급수적으로 증가하기 때문에 동일한 개수의 데이터의 밀도는 차원이 증가할수록 급속도로 희박(sparse)해짐→ 차원이 증가할수록 차원 내에서 빈공간이 늘어나 데이터의 밀도가 희박해지는 것
- → 차원이 증가할수록 기계학습에 필요한 데이터의 개수가 기하급수적으로 증가하게 됨
- 그러나 특정 공간 대비 희소한 데이터 양임에도 불구하고 성능을 예상할 수 있음
- 희소 특성 가정 data sparsity : 고차원 특징 공간에서 실제 데이터가 발생하는 영역은 매우 희소한 공간
- → 예를 들어 사람이 봐도 이미지가 숫자가 아닌 경우는 특징 군집에서 멀어져 있으며 관찰 데이터들이 희소하다.
- 매끄러움 가정 : 일정 규칙에 의해 차원 간의 매끄럽게 변화하는 양상을 가짐→ 이러하게 유사한 규칙에 의해 발생되는 확률 가지는 것임
- → 예를 들어 2숫자를 보이는 사진의 2 각도가 살짝 달라져도 계속 2인 것처럼 2라는 숫자를 가리키는 이미지들은 규칙이 유사함
- 매니폴드 가정 manifold : 고차원의 데이터는 관련된 낮은 차원의 공간의 조합으로 구성됨→ 예를 들어 위에서 찾은 멀쩡한 숫자들을 특징하는 공간은 희소하고 고차원의 데이터에 내제되어있는 히든 패턴인데, 이 히든패턴에서 낮은 차원의 공간의 조합을 찾아내면 저차원으로 추상화가 쉬워지는 것
- → 고차원의 데이터에서 핵심 저차원 공간으로 축소 및 표현학습을 통한 추상화 가능
- 예를 들어 MNIST가 28*28(흑백이라 1 or 0)차원으로 구성이 된다고 가정하면 서로 다른 경우의 수는 총 2^784가지인데 MNIST dataset은 6만 개로 차원에 비해 매우 희소한 데이터 양이다. 그럼에도 성능을 예상할 수 있는데 그 이유는?
- 데이터의 양이 늘면 기계학습 모델의 자유도가 높아짐
- → 자유도가 높아지는 것은 모델이 표현할 수 있는 파라미터의 갯수가 늘어난다는 것
- 데이터의 질을 고려하지 않으면 의도치 않은 편향성이 생김
- 데이터의 양이 늘면 기계학습 모델의 자유도가 높아짐
4. 기계학습 개요
기계학습 예시
신용 승인 사례의 교사 학습을 예시로 들면
기계학습 요소 component
교사 학습 예시
신용 승인을 받고 싶은 사람의 나이와 소득을 x로 두고 이 두가지가 신용 승인 사례에 어떻게 영향을 끼치는지 보는 것이다.
가설은 g, f가 눈에 보이지 않는 실제 p(x|y)
사진 처럼 가설은 반드시 좋은 가설이라고 할 수 없다. f에 따라 새로 만들어진 데이터 세트가 g에 맞지 않을 수도 있다. 이럼 해당 인공지능은 성능 좋은 인공지능이라고 할 수 없다. → 그래서 데이터의 편항에 주의해야한다.
기계학습 모델이 트레이닝 되는 과정은 이렇다.
기계학습 모델 개발 작업
가설-연역적 연구 방법과 유사하다.
기계학습 예측 문제 구분 prediction
- 회귀 regression : 목표치가 실수 (연속적인 값 continuous values)
- 분류 classification : 목표치가 부류 혹은 종류 (불연속적인 값 discrete values)
데이터의 구분
- 훈련 데이터집합 training dataset : 연습문제
- 검증 데이터집합 validation dataset : 모의고사→ 훈련 때 안 쓰는 데이터
- → 같은 데이터 셋으로 훈련한 모델들 중 최적화된 모델을 선택하기 위한 검증 데이터
- 시험 데이터집합 testing dataset : 수능
목적함수 objective function
→ 성능 performance, 오차 error, 비용함수 cost function 이라고도 함
→ 정량적인 성능 판단 지표
→ 학습이 진행될 수록 점차 개선되어야 함
→ MSE (평균제곱오차) 방식이 많이 쓰인다.
기계학습
기계학습을 통해 관찰된 데이터집합의 규칙을 찾음 → 가장 정확하게 예측할 수 있는 모델 찾음 → 일반화된 성능 보장이 목표
given - x가 시간, y가 이동체 위치인 4개의 관찰 데이터
prediction - 임의의 시간에서의 이동체의 위치 예측
위의 given과 prediction에 대한 문제를 예제로 들어 기계학습을 시켜 본다면?
1. 가설 : 눈대중으로 봤을 때 직선을 이루니 선형회귀 linear regression 모델 선택→ d차원 : $y=w_1x_1+w_2x_2+...+w_dx_d+b$
→ 직선의 모델 수식 : y=wx+b로 w, b 두 개의 학습 매개변수 존재
2. 훈련 training 과정 : 가장 정확하게 예측할 수 있는 최적의 매개변수 찾음
→ 처음은 임의의 값, 점점 예측 성능을 개선
3. 추론 inference 과정 : 새로운 특징에 대응되는 목표치 예측
학습 알고리즘 (의사 알고리즘 pseudo algorithm)
- 최적의 매개변수를 찾는 행위
- 실제 현실의 데이터집합은 완벽한 선형이 아니고 잡음도 많음
- → 선형 모델로는 일반화된 성능을 보장할 수 없음
표현 문제 representation matter
- 직교 좌표계를 원통 좌표계로 표현 방식을 바꿀 수 있음
- 선형 분리 불가능 linearly non-separable 특징 공간
- → 식을 통한 새로운 특징 공간 변환
표현 학습 representation learning
- task에 유리한 특징공간을 자동으로 찾는 작업 : 추상화 = 특징 추출 = 공간의 변화 = 표현의 변화
심층 학습 deep learning
- 표현학습의 종류 중 하나임
- 깊은 인공 신경망의 다수의 은닉층 hidden representation을 이용해 점진적으로 표현 학습 (3장에서 자세히)
5. 과대적합 과소적합
학습 모델과 용량 capacity
- 학습 모델의 매개변수의 수, 자유도, 모델 용량은 비례한다.
- 과소적합 : 모델의 용량이 작으면 오차가 큼
- 과대적합 : 모델의 용량이 크면 학습 과정에서 불필요한 잡음 혹은 훈련 데이터집합에만 과대 몰입해 일반화 성능을 보장할 수 없음
- → 새로운 데이터 예측인 경우 예측이 크게 엇나가는 경우 발생
- → 일반화 성능 보장 x
- → 주어진 훈련 데이터집합에 대해서는 거의 완벽하게 근사화
- 실제론 overfitting 문제가 많이 생김
편향 bias 과 변동(분산) variance
- 작은 용량의 모델은 bias↑, variance↓
- 큰 용량의 모델은 bias↓, variance↑
→ bias와 variance 는 상충관계trade-off
- 학습 모델의 일반화 성능 Generalization error : bias error + variance error
- → 곡선 형태는 u자 형태
- 학습 타당성 Feasibility of learning
- → 근사화 approximation : $E_{in} \approx 0?$ 추출된 dataset의 일반화 성능은 0에 가깝나?
- → 일반화 generalization : $E_{out} \approx E_{in}?$ 실제 모든 dataset과 일반화를 위해 추출된 dataset은 비슷한가?
- 과소적합일 경우 과대적합 방향으로 나아가야함 → 규제 regularization 필요
- 과대적합일 경우 과소적합 방향으로 나아가야함 → 향상된 최적화optimizer 방법 적용
학습 모델 선택
검증 validation dataset 이용
- training dataset / validation dataset / test dataset 으로 나눔
교차 검증 cross validation dataset 이용
- 데이터 수집량이 적어 validation dataset이 없는 경우 이용
- 만약 k개의 training dataset이 있으면 이걸 k개의 training dataset+validation dataset 조합으로 나누는 것→ 하나의 validation dataset으로 성능 확인
- → 위 두 과정을 계속 반복하며 몇번째 조합으로 기계학습한 모델의 성능이 가장 좋은지 확인하고 선택
- → j번째 dataset을 validation dataset으로 설정하고 나머지 k-1개의 dataset을 training dataset으로 설정한 후 training 진행